You can connect with me on LinkedIn to discuss collaborations and work opportunities.
Some context
This post is mainly a technical post on what's the status of the pandas documentation. But let me provide a bit of context on where this comes from.
It's a personal opinion, but I think pandas is one of the clearest examples of how open source is transforming the data world (together with some other projects like scikit-learn, Jupyter, R...). Is likely that pandas contributed to the huge growth of Python, a language that not many people knew about when pandas development started.

And I think its documentation has been the clearest example of the paradox of open source software. While pandas users were growing to the millions, and it was adopted in thousands of companies (including the largest companies in the world), almost nobody spent any time or money in its documentation (which requires a lot of work to be of high quality). It's surely not to blame the very few people (3 or 4 at times) who were maintaining the project. They had enough dealing with thousands of issues, updates in the many and fast changing dependencies, releasing new versions... While also implementing new features and fixing bugs themselves. And even more considering that most of that work was done as volunteers, in evenings after work or in weekends.
More than 2 years ago I sent to the project my first pull request, fixing a single docstring (one of the around 2,000 in the project). And decided to spend a significant amount of my also volunteer time (after work and during weekends) in improving that part. That also was one of the main reasons for starting the Python sprints group.
More than two years later, not much changed (apparently). But if you care about my opinion, I'm sure very soon pandas will have one of the best documentations of any open source project. This post explains all the work done by hundreds of people in the last couple of years, and the work that is still missing, and how we are going to approach it.
If you work for a company that is making money using pandas, and that would be more productive and make even more money if pandas documentation was better, please contact a pandas maintainer including myself or NumFOCUS. We are happy to discuss funding opportunities, including small grants or helping your company hire people to work on pandas.
The problem with the docstrings
The pandas API is huge, and includes around 2,000 functions, methods, classes, attributes... Each of them with a page in the documentation. Given the very reduced number of developers pandas had, and the huge demand and urgency for a dataframe library in Python, most of those API pages couldn't be created with high standards when the features were implemented. See for example the Resampler.last page.
It may not be obvious for people who haven't contributed to a project like pandas before, but improving a docstring, and make it as useful for readers as possible, it's not 5 minutes of work. Based on the work done by lots of contributors over the last year, I would estimate it takes around 1 day of work of an experienced pandas user. You can see the docstring of Resampler.bfill to see what I'd consider a good docstring.
Considering this estimate of 1 day per docstring, and the around 2,000 docstrings, it's easy to calculate that it'd take around 8 years for a single person working full time, to have all them fixed. And that excludes the time of maintainers to review the changes, provide feedback, merge...
The pandas documentation sprint

As it's obvious that a single person can't do much, one of the things that was tried was to organize a worldwide pandas sprint.
The sprint was extremely successful in many ways. 30 local users groups participated, from places as diverse as Korea, Hong Kong, India, Turkey, Kenya, Nigeria, Argentina or Brazil, besides many cities in Europe and US. Difficult to say how many people participated, but we estimate there where around 500 people helping make pandas documentation for a whole Saturday.
I think there are no words to describe how amazing that is. How many people offered to organize sprints with their local groups. And how many people joined them in every sprint. The organizers had to prepare the event for weeks, both for logistics but also for the technical part of leading a lot of people in their first open source contributing.
A big responsible for this success was NumFOCUS. For several years now NumFOCUS has done extraordinary efforts on building the PyData community. Having a connected network of more than 150 user groups made it very easy to communicate and reach all the people who could be interested.
The feedback I received from the participants and organizers was very positive, and people enjoyed the experience (which I personally think it's much more important than the contributions made). And there were around 200 documentation pages that were fixed because of the sprint (10% of the total).
But not everything was so positive. The sprint also made evident that the problem of fixing the documentation was not the number of contributors. The bottleneck happened to be the maintainers. The sprint created a total disruption of the project for more than two weeks. And this period wasn't longer because the maintainers were spending day and night reviewing the pull requests from the sprint. In many cases it was the maintainers who had to finish the work started during the sprint. Many pull requests contained great work, but were discontinued, and they required important changes that had to be done by the maintainers. The last PR from the sprint was merged almost a year later than the sprint.
More information about the sprint can be found in this NumFOCUS write up.
The validation script
We anticipated before the sprint, that reviewing the contributions would be a lot of work. And we developed a script to automate part of it. The idea was to automatically detect things like:
- The documented parameters of a function need to match the actual parameters in the signature
- Conventions like starting sentences with a capital letter or finishing with a period
- Ensure that some sections we'd like to always have are present (like Examples)
- Formats that make Sphinx render the documentation incorrectly, like missing spaces before the colon between a parameter name and its type
We managed to have several of these ready for the sprint. But to keep all the docstrings consistent and rendering correctly, we needed many more. Many people spent a significant amount of time adding new checks to the script, and we are currently able to automatically detect more than 40 possible problems in docstrings.
Of course not everything can be validated, think of correct grammar, wrong, inaccurate or misleading information, examples that are not clear... But validating almost every formatting issue automatically will definitely save a lot of time of reviewers. Who will be able to focus on the things that can't be automated.
Some other projects had interest in using our validation script, so it's been recently moved to numpydoc

Continuous Integration
During the sprint, we provided clear instructions, and we had mentors in each of the 30 different locations. So, everybody was probably aware that the validation script was one of the main things they had to check. But regular contributors don't get this sort of induction. So, ideally we would like to run the checks automatically in the CI, so contributors are aware of any problem in their proposed changes. But there are some things to consider.
With Travis, our main CI system, the errors ended up in a huge log, that only experienced pandas developers are able to understand. See for example this job and make sure you wait until it's fully loaded. :)
Luckily, at the time our script was being implemented, Numba set up Azure Pipelines for their CI, and we decided to use it to complement Travis. The main reason was that we required more computational power for the huge test set of pandas, and the large number of builds. But, I think the clarity on how the errors can be reported, is as convenient as the 30 concurrent jobs the Azure team offered us. Compare this with the previous Travis log:
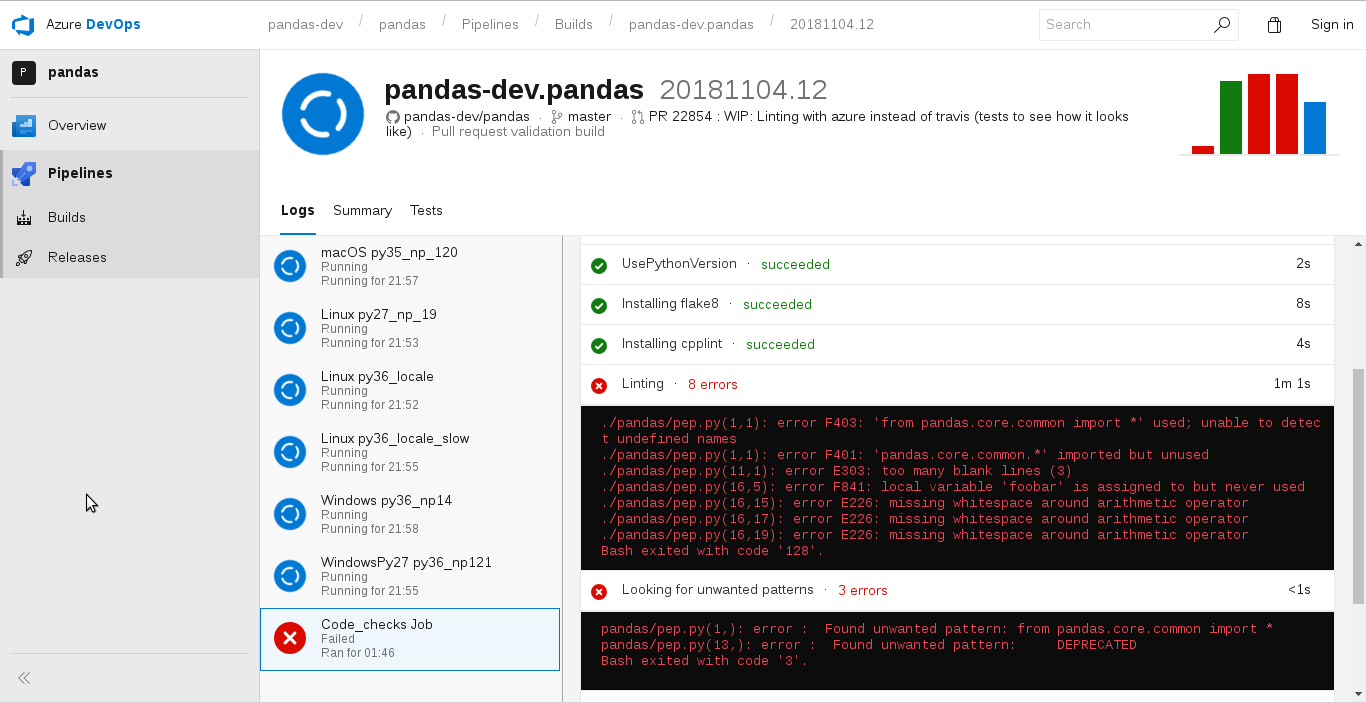
We were very ambitious, and somehow pioneers in what we were doing, and it wasn't easy to get what we wanted. But The Azure team was extremely helpful, and the final presentation of errors in docstrings, as well as the linting errors and others was much clearer. And friendly for first time contributors.
Azure pipelines was an improvement, but we still had some challenges. The integration with GitHub wasn't great, and it required following two links and navigating a somehow confusing interface to arrive to the page where the errors were being presented in a better interface than TravisCI.
Just few days ago we moved this docstring validation, among other things, to GitHub Actions. So far the experience has been great, and we keep the same advantages as with Pipelines, and also we have a better integration of the CI with GitHub. And the configuration is also simpler and a bit more intuitive than with Pipelines.
We are still figuring out how to notify contributors with a human-readable message about problems in the CI. Since only experienced contributors know how to find the problems by themselves. And that's taking time from the reviewers, for a task that could be easily automated. With GitHub Actions is very easy to write comments in a pull request, so the only remaining challenge is to obtain all the failures in all the jobs in a run. But hopefully that's not too complex and we can have it in place soon.
Another important thing that the continuos integration can do for us, is to let us visualize the documentation before being merged. In many cases, small details make the documentation render in an incorrect way. Like a bold style that doesn't finish when it's expected to finish. Or a broken table that renders as plain text.
This has been challenging until now, since CI systems don't do this automatically, and it's tricky to implement manually. CircleCI provided this feature, but to access the rendered documentation you have to know the url and replace the id of your build on it. Maintainers could do that in a not very efficient way, but first-time contributors couldn't guess.
Implementing it manually has a main challenge. The CI is usually only able to access passwords and keys when a pull request is merged. Otherwise a malicious pull request could access the key and leak it. An option to overcome this limitation would be to host in a server a GitHub application that receives a webhook when a pull request is opened or updated, and its docs are built. After being triggered it would fetch the docs, and publish them somewhere, using a key only accessible in the server.
Implementing that has been in our backlog for a while. But there is another problem. Where to host all these copies of the documentation. We use GitHub pages to host the latest version of our docs. But since Git/GitHub track all the history of changes, the repo would grow huge very quickly if we add all our docs (around 50Mb) for every pull request.
The solution to this may come easier than expected, since GitHub Actions seems to be consideting implementing it. Not sure when that could be ready, if ever. In the meantime OVH has recently started sponsoring a new pandas cloud hosting, were we can temporary store all these versions of the docs. This is being implemented now, and with some luck should be in production soon. If we implement our GitHub app to publish the docs, the new hosting and GitHub Actions will make it much easier than it was before. GitHub Actions will also make very simple to delete the docs for a PR once it is merged or closed.
Validating docstrings in the CI
Two key pieces to validate contributions to the pandas docstrings are in place:
- A validation script with lots of checks
- A CI system friendly with first time contributors
But there is a last piece needed. If we activate the validation in the CI, we will have 1,000 docstrings, or more, reporting errors in the CI for every PR. Basically, we will be reported of every error in every docstring that needs to be fixed every time the CI runs.
Would be useful to be able to get the errors being introduced, so no more errors are added, while we fix the ones we already have. But this is not feasible (would be too complex and too slow).
This leaves us in a unfortunate position, of only being able to validate what has already been fixed. Which is extremely useful, as we can guarantee that things don't get worse. But it doesn't solve our problem of improving the docstrings that need it yet.
So, what can be done? I think it's useful to divide the docstring checks in two different categories:
- The pure formatting things (like having periods at the end of sentences)
- The ones that require knowledge of pandas and the object being documented (like adding examples of how to use an function, or adding an undocumented parameter)
The ones in the first category are somehow easy to fix. And many can be fixes at a time (in a single pull request), working in one after the other, without stopping much to understand things.
Once all the errors of a kind have been fixed, we can start validating that specific error in the CI. And we guarantee that no more errors of that kind will ever happen.
And what is even better. Once all those formatting errors are fixed, we can start working on the docstrings, one at a time. Where a person spends enough time understanding the function being documented to become an expert. To a point where it can focus on improving the content, writing a nice summary, useful examples, and document parameters in an accurate way. And that person won't need to become an expert in reStructuredText formatting, because the CI warn about any issue. And the person will be able to fix any problem without requiring time from a maintainer.
We already completely fixed several of the more than 40, and we validate that the errors are not added again:
- GL03: Use of double blank lines when one would be expected
- GL04: Private classes mentioned in public docstrings
- GL05: Tabs used instead of 4 spaces
- GL06: An unknown section is found
- GL07: Sections in the wrong order
- GL09: Deprecation warning in the wrong position
- GL10: Sphinx directives incorrectly formatted
- SS04: Summary contains heading whitespaces
- SS05: Summary staring with infinitive verb, not third-person
- PR03: Parameters are in the wrong order (compared to the signature)
- PR04: Parameters without type
- PR05: Parameter type finishing with a period (it shouldn't)
- PR10: Missing space before colon splitting parameter name and type
- RT01: No Returns section
- RT04: Returns description should start with a capital letter
- RT05: Returns description should finish with a period
- SA01: No See Also section found
- SA02: See Also description should finish with a period
- SA03: See Also description should start with a capital letter
- SA05: Unneeded prefix in See Also section object
- EX04: pandas or NumPy explicitly imported in the examples (we assume they are always imported)
Those validations have been added to the code_checks.sh script, which is responsible for many code quality checks (linting, typing, avoidance of unwanted patterns...).
But there are still many errors that need to be fixed, including formatting errors.
We are able to get the list of all the errors that we can automatically detect, with the same script that analyzes a docstring, but without passing an object as a parameter::
$ ./scripts/validate_docstrings.py --format=json > docstrings.json
This will output a JSON file that can easily be loaded into pandas, and see what needs to be fixed:
import pandas
(pandas.read_json('docstrings.json', orient='index')
.loc[:, 'errors']
.map(lambda err_list: '|'.join([err[0] for err in err_list]))
.str.get_dummies('|')
.sum(axis='index')
.sort_values()
.plot.barh())
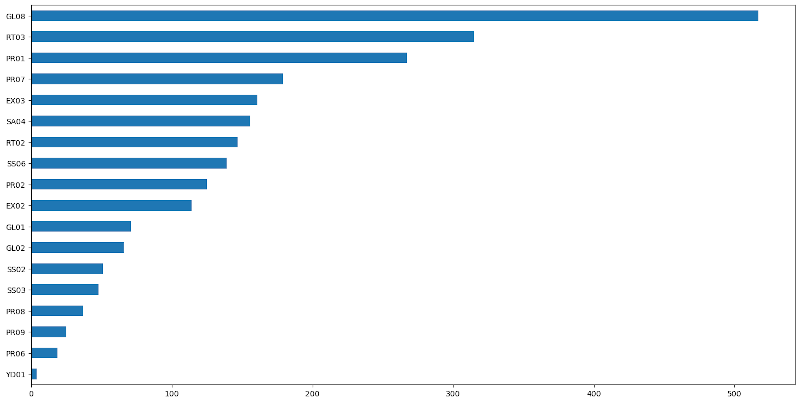
We can see how there are 18 different validations with docstrings that don't pass them.
The list of all the validations and their error codes can be found in the same validation script code.
We can see for example, how the error GL08, happening more than 500 times, means that
the objects don't have a docstring at all. See for example
Series.empty
Or the second most frequent error, RT03
means that it is not documented what is being returned (the return type is present, but
there is no description on what's the returned object).
In total we have 2,441 errors that we can detect automatically. That includes docstrings that need to be fully created. And creating them requires a lot of time, since there is no documentation of them, and analyzing the source code, experimenting... is required.
Where do we come from?
Analyzing the docstrings of past versions of pandas we can see that pandas 0.23 had 7,136 errors, with the current validations. pandas 0.23 was released on the 16th of May of 2018, couple of month after the worldwide sprint with 500 people. Most of the work of that sprint was already present in that version.
This is the detail of errors at that time:
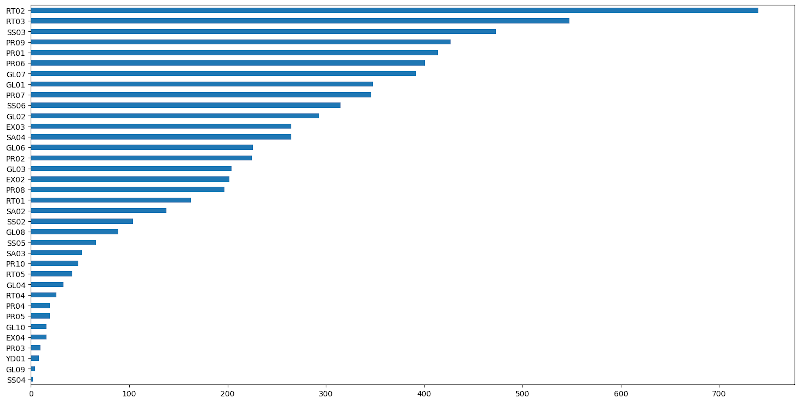
So, in 18 months we fixed two thirds of the errors. Assuming it takes the same amount of time to fix every error, and that we continue at the same pace, in 9 months more we should have all them fixed. This would amazing, but it's clearly false that all errors require the same time, and it's obvious that we started by the easy ones. But we are getting closer.
Parallelization, a game changer
Our work is every time more challenging and time consuming. Remember that we started with small formatting changes like adding a period at the end of a sentence, and we are going to write full docstrings. So, we need to become smarter and more efficient on how we work on the documentation. And the most important part is being able to work in parallel, since there is not much a single person can do.
Of the around 2,000 docstrings, around 1,400 still have errors (considering errors detected by the script). Imagine that tomorrow we want to start working on all them. One of the main problems would be to detect who works on what, and avoid duplicate work. Many people volunteered in the past to help make the pandas documentation better, and there may be 1,400 people out there who could be happy to help if they knew exactly what to do.
How this is usually solved in open source is by creating issues. Then people assigned the issue they want to work to themselves, and as people join the party, they check in the list of unassigned issues what else need to be done.
Unfortunately, a workflow as simple as this has been problematic in GitHub. While GitHub provides a nice interface for issues, and implements the functionality of assignees, it's limited to members of the organization (core developers). While this is useful for small corporate projects, assignees is unused in pandas, and people have been assigning them issues by mentioning their interest in a comment. Which it kind of works, but it doesn't let people find unassigned issues in an easy way.
Recently, we found a hack in pandas, that people is starting to use. With GitHub actions, we are able to assign issues to people who adds a comment with the exact word `take. While this is far from optimal, since most users won't be aware of this, it can be very useful when organizing sprints or coordinated events, where we can communicate with contributors. We can also write in the issue description about this new feature, so creating a batch of issues automatically, that we expect people to assign to themselves seems feasible.
That's a game changer in parallelizing the work, since it makes the logistics much simpler in coordinating the contributors. See more information about this new workflow in this recent blog post I wrote.
But there are still some challenges:
In many cases, pandas has templates for a docstring, that are reused in more than one object. So different objects can use the same docstring, and it's not easy to identify which. Creating issues automatically for each object can still cause overlap in the work.
While many things can be automated, the main bottleneck are still the reviews of the changes. There are few people who has the knowledge and experience in pandas to provide feedback on whether the changes to the documentation are reasonable. And who has the permissions to merge changes into pandas. And almost all them are volunteer, and need to take care of other obligations like full time jobs and family.
The future

Exciting times are coming for the pandas documentation. Not only the content, but also a whole new theme is being implemented. So, soon the documentation will look much better.
The CI is getting closer to a level where we can automate as much as possible, and be very efficient in coordinating the documentation efforts. As well as let first-time contributors be quite autonomous, and progress independently on their work until a maintainer can really add value.
Not only the number of maintainers in the project has been growing significantly in the last couple of years, but a new role of triaggers has been implemented, which can be useful in this effor.
NumFOCUS has recently awarded us a small development grant to work on the documentation. And not only will help with the documentation but hopefully will address a problem as big as it, diversity. A group of people from groups underrepresented as pandas contributors will be helping with the documentation, and organizing sprints in different locations to help and encourage more people to contribute to it.
Increasing the diversity of the background of the contributors, will not only help with the quantity of the documentation pages, but also its quantity. pandas should be useful for a wide variety of people. If the documentation is made and reviewed by people from different backgrounds (academic backgrounds, geography, gender...) it will be clearer and more useful to more people, and will better accomplish its goal.
The sprints are likely to be in Jakarta, Cairo and Berlin. If you can increase the diversity of the pandas contributors and want to participate, feel free to contact me for more details and updates.
If you would like to organize a pandas documentation sprint for minorities in a different location, please also get in touch. We are unlikely to be able to provide funds, but we can help you with everything else.
And if your company would benefit from a better pandas documentation, please consider supporting the project. From funding to the project, to funding of specific developments. And also you can consider hosting an event in your office, letting your employees spend part of their time working on pandas, providing in-kind donations, or anything you can think of. Please message me or any other maintainer to discuss about opportunities.