You can connect with me on LinkedIn to discuss collaborations and work opportunities.
The past 10th of March took place #pandasSprint. To the best of my knowledge, an unprecedented kind of event, where around 500 people worked together in improving the documentation of the popular pandas library.
As one of the people involved in the organization of the event, I wanted to write about why I think this event was much more than the contributions sent, and the fun day we had. And also provide information on how it was planned, to help future organizers.
Some historical context
To explain where the idea of the #pandasSprint came from, I need to go back in time more than 15 years. Those were the times where open source was named free software, people queued to see Richard Stallman talks, and companies like SCO and Microsoft were in the dark side of proprietary software. Free software was more about freedom than about software, and the free software community was working hard and united to build the software that could challenge the status quo.

Now we’re in 2018, and things changed a lot. SCO doesn’t exist anymore, and Microsoft is one of the companies supporting more open source. Employing more Python core developers than any other company, sponsoring major events like PyCon or EuroPython, and funding non-profits like NumFOCUS, The Python Software Foundation and even The Linux Foundation. Python is growing in popularity, and nobody questions the advantages of open source software.
But what happened to all the free software hackers who untiringly were making their projects be to the highest standards? Of course there are still many people there, but my perception is that the growth in popularity of open source projects didn’t translate linearly to a growth in the number of contributors. And I think pandas is one of the clearest examples.
For the last years, pandas has been becoming a de-facto standard in data analytics and data science. Recently, Stack Overflow published that almost 1% of their traffic from developed countries is caused by pandas. The book Python for data analysis by pandas creator sold more more 250,000 copies, and the pandas website has around 400,000 activeusers per month. It’s difficult to know how many pandas users exist, but some informed opinions talk about 5 million.

What about the contributors? In a quick look at GitHub, I counted 12 developers that have been active in the last year, and that contributed more than 20 commits to the project. This leaves a ratio of 1 significant contributor for more than 400,000 users. Not long before the #pandasSprint the project achieved 1,000 contributors. Meaning that 1 in each 5,000 ever made a contribution.
You can find these small or big depending on your expectations. And it’s difficult to compare without numbers about Python projects 10 years ago. But my feeling is that we transitioned from a free software community of developers actively participating in the projects, to a community of mainly users, who in many cases see free software as free beer.
How to become part of the open source community
I don’t know why people become part of the open source community, in terms of participating actively on it. But I know how I did. It’s a beautiful and sad story that I want to share.
Around 12 years ago, I was quite new to Python, but really liking the language compared to what I used before. Most of what I was doing was web based, so I quickly discovered Django, and felt in love. What in PHP (the de-facto standard at that time) took one week or more to implement, in Django was done in minutes, and with much higher quality. Django was simply amazing, the web framework for perfectionists with deadlines. But in some areas not as mature as it is now. And I’m talking mainly about localization. The system to translate static text was amazing, but you couldn't make calendars start in Monday, or use the comma as a decimal separator. That was a big problem for me, as my users in Spain wouldn't be happy using the US localization. The good news was that it was open source, so I started to take a look on what could be done.
When I submitted my first bug reports and patches to Django, I found the best mentor a newcomer to open source can find, Malcolm Treddinick. He was the core developer more involved in the localization part of Django. Malcolm helped me in every step, and I learned a lot from him about Python, Django, subversion... But I also learned from him (and also from others in the community) about kindness and collaboration. It was a really welcoming community, and honestly, at the beginning I found it quite surprising the amount of time people was happy to spend helping and giving support to someone who didn’t have so much to contribute. After some time, I managed to be more experienced, and I was able to contribute back, taking care of the Catalan and Spanish translations for some years, and doing a major refactoring of Django's localization system, as part of a Google summer of code. But who could know that beforehand.

I was in shock when in 2013 Malcolm passed away. Besides being a tragedy for him and his close ones, it was also for many of us, who barely met him in person, but considered him a friend. The Django Software Foundation created the Malcolm Tredinnick Memorial Prize in his honor. The prize is awarded, quoting the DSF page “to the person who best exemplifies the spirit of Malcolm’s work - someone who welcomes, supports and nurtures newcomers; freely gives feedback and assistance to others, and helps to grow the community”.
Malcolm was unique, but the open source community is the amazing community it is, because there are so many amazing people who exemplifies the spirit of Malcolm every day.
London Python Sprints
So, with such an amazing community (and I experienced it enough to be sure about it), what is it preventing more people to get involved? I would say most people thinks that technically speaking, they are not good enough for the projects. That you need the mind of Alan Turing, Dennis Ritchie or Linus Torvalds to make a contribution. I strongly disagree. Even the less technical people can participate in many things such as translations, writing documentation, ticket triaging… There are also many great projects in their early stages were contributing code is much easier than contributing to the more complex and intimidating ones.
Then, what’s the problem? Personally, I think the only problem is getting started. The first time, it’s difficult to find a task to get started. It’s difficult to understand the logistics of sending a pull request. It’s difficult to know beforehand whether project maintainers will welcome our small contributions. And it may be difficult to even know that we need a task to work in, that we need to send a pull request, or that there is a community out there working on every project. But these are just difficult until someone is able to help you get started.

With this idea in mind, London Python Sprints was born. A place where open source contributors could mentor newcomers in their first steps. And personally, I think it’s very successful. Not only we managed to send around 50 pull requests to different projects in 2017, but people who did the first pull request with us, are now the mentors helping others get started.
#pandasSprint: the idea

While the experience in London was great, it was very low scale. And we could do much better. All it takes for many people to love becoming a contributor, is to have some guidance in these first steps. We already had the experience from several months of sprints in London, and with some preparation we could help other user groups do the same.
Why pandas? There are plenty of great projects to contribute to. But for pandas... Everybody loves pandas, it’s very popular. It’s a welcoming project in the spirit of Malcolm. Improving the documentation would be something very useful. And it’s one of the projects I’m more familiar with
But it’s probably clear that the goal wasn’t that much about the specific project or contributions. But about letting people get into the open source world in the way many of us love it. Becoming part of it, and not just being a user of some software we don’t need to pay for.
#pandasSprint: the implementation
So, we wanted to have a huge open source party, but of course that required a huge amount of work.
The first thing was to make sure the pandas core developers were happy with it. It was going to be a lot of work from their side, and they know much more about pandas than anyone else, and could tell whether it was a good idea, or provide useful feedback. An email to Jeff Reback was enough to start. He loved the idea, even if I think he didn’t believed at that time it was going to be something as big as it finally was. :)
Dividing the work
The next thing was to make sure everybody had something to work on the day of the sprint. Working on the documentation made it possible. There are around 1,200 API pages in the pandas documentation. Writing a script to get the list was easy. We could even gather some information on the state of the documentation (which pages had examples, which methods had mistakes in their documented parameters...).
The trickiest part was the system to share docstrings in pandas. There are many functions and methods in pandas, that are similar enough to have a shared template for the documentation, customized with few variables specific to each page. The original idea was to use Python introspection system to find the exact ones sharing a template, so we could avoid duplicates. That was more complex than it originally seemed, and we finally delegated the task of finding out to each user group. To help with that, we divided the pages in groups by topics, and assigned whole groups to each sprint chapter. Sharing of docstrings was more likely to happen inside these groups. For example, all the functions in Series.str where in a group. Functions like lower(), upper(), capitalize() use the same template, so it should be somehow easy to detect it in the chapter working on that group.
Documentation
Then, after being able to provide each participant a task, we had to make sure everybody knew what to do. For it, there were two main things. First, having documentation explaining all the steps. And second having mentors in every city.
For the documentation, we had 3 main documents: - Set up instructions (installing requirements, cloning the repository, compiling C extensions...) - Guide on how to write a docstring for pandas - Instructions on how to validate the changes, and submit them
The most complex part was defining how a “perfect” docstring had to look like. Following some standards would be very useful for pandas users. All the pages would be implemented in the best possible way we could think of. And users would be able to get used to one format, and find information faster.
We started with a draft of a guide in the form of pull request, so everybody could review and add comments. And then it was a bit of discussion on the topics with disagreements or unclear. I think the result was great. But of course we couldn’t anticipate all the cases.
We also had to write documentation about shared docstrings, and what was the preferred way to implement it. Tom Augspurger took care of it.
Mentoring
A key thing was to make sure in every location we had people who could mentor participants. We created a gitter channel for the event, but it would be difficult to remotely help in more than specific things. Everybody was in their own local sprint, and we also had different time zones, so availability during the sprint would be limited.
So, what we did was to ask somebody from each chapter to work on a taskbefore the sprint. In most cases that was the same organizers. I don't know if that is true, but I had the feeling that some organizers were underestimating how complex improving a single API documentation page is. And how difficult is to help a large group of people who is doing their first open source contribution can be. Letting them prepare before hand should be useful in different ways: Organizers would be better prepared, and have a better sprint, without so much stress and uncertainty. They should be able to help participants better. The "mini" sprint of the organizers would be a proof of concept that would let us anticipate problems in the documentation, the procedure...
Not all the organizers found the time to prepare, as we were ready to start this stage less than a week before the global sprint date. But I think it was very useful for the ones who could prepare for the sprint.
Tools
One of the areas we worked on preparing the sprint, was in having better tools. Joris Van den Bossche, besides being key in all the parts of the sprint, did an amazing job on this part. We implemented a way to build a single document in Sphinx, and a script to validated formatting errors in docstrings. We also set up a sphinx plugin to easily include plots in the documentation, which made some pages look really great.
Last minute, we also build a dashboard with a list of checkpoints that the users could follow during the day, so it was clearer to know what to do, and it should help them make better contributions.
Promotion
Promoting the event, and finding the people willing to participate was done in different ways: The first one was to direct message the organizers of different communities. Among all the great things of the Python community, is how well organized it is. In a single page there are the links to the almost 100 PyData meetups all around the world. In the Python website there is a wiki with tens of Python user groups. Not everybody we contacted was interested, or even answered, but most of the groups were really happy with the idea.
The Python Software Foundation, NumFOCUS were also key in spreading the word about the event.
As the sprint was to work on the documentation, we also contacted Write the docs, a global community focused on writing technical documentation. Some of their members joined the sprint too.
The sprint
For the day of the sprint, we've got a last minute surprise. I really think what every participant of the sprint was going to do, was something really great. Even if in a way it felt more like a Saturday with friends. And I think it was worth that people knew how important is to contribute to the open source projects that power from the scientific research to the financial markets, or the data science infrastructure of so many companies in the world. So, just few hours after the sprint we spoke with Wes McKinney, creator of pandas, Naomi Ceder, chair of the Python Software Foundation, and Leah Silen, executive director at NumFOCUS, to see if they could record a short message to the participants. Even with the very short notice, all them sent really great messages that we could show the participants at the beginning of the sprints.
It's difficult to know what happened in the sprint at a global scale. I think in London we've got a great time, with nice atmosphere and a luxury location provided by our sponsor Bloomberg. I think for most of us the sprint seemed too short. Even if I think it was a typical British pub follow up to the sprint, that I couldn't join.

In other locations, for what I know the experience was also good. It's worth taking a look at the twitter feed of the sprint.




Also, I really enjoyed reading the write-ups that some organizers and participats wrote: - From Iva and Tsvetelina, organizers in Sofia: - From Priyanka, a participant in Amsterdam: - From Himanshu, organiser in Kanpur, India: - Live streaming of the sprint in Shen Zhen: - From Marc, participant in Toronto: https://towardsdatascience.com/making-my-first-open-source-software-contribution-8ebf622be33c - From Bluekiri, sponsor in Mallorca:
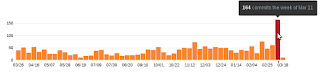
And it's worth taking a look at this analysis on the impact on the sprint in the pandas GitHub activity by Joris: https://jorisvandenbossche.github.io/blog/2018/03/13/pandas-sprint-activity/
#pandasSprint aftermath
This is what I think was the aftermath of the sprint: - A lot of hard work before the sprint by all the local organizers and core developers - More than 200 pull requests sent, around 150 already merged - Many people really loved the experience - An incredible work by the pandas core development team after the sprint - In London, our sprint after the 10th of March have long waiting list, which was not happening before the #pandasSprint - Several people keeps contributing to the pandas documentation after sending their first contribution
And what I think it's more important. We did a small but great step in making sprints a popular event format in the Python community, to add the missing piece to the numerous conferences, meetups based on talks, dojos, workshops and others.
Several people asked me when is the next one. In London we are having two sprints this week. Man AHL is hosting this great hackathon in one month. I hope to see other user groups organizing sprints in the future. And about another worldwide sprint... May be in some months we could do a PyData Festival and have 10,000 people contributing to 20 different projects during a whole weekend? :)